$ 0.000 0.13%
CNNS (CNNS) Rank 2439
| Mkt.Cap | $ 48,974.00 | Volume 24H | 692.41 MCNNS |
| Market share | 0% | Total Supply | 10 BCNNS |
| Proof type | N/A | Open | $ 0.000049 |
| Low | $ 0.000048 | High | $ 0.000052 |
machine learning
Because the CNN looks at pixels in context, it is able to learn patterns and objects and recognizes them even if they are in different positions on the image. These groups of neighboring pixels are scanned with a sliding window, which runs across the entire image from the top left corner to the bottom right corner. The size of the sliding window can vary, often we find e.g. 3x3 or 5x5 pixel windows. These pixel arrays of our images are now the input to our CNN, which can now learn to recognize e.g. which fruit is on each image (a classification task). This is accomplished by learning different levels of abstraction of the images.

The computation speed increases because the networks are not interacting with or even connected to each other. Here’s a visual representation of a Modular Neural Network. This type of neural network is applied extensively in speech recognition and machine translation technologies. The radial basis function neural network is applied extensively in power restoration systems. In recent decades, power systems have become bigger and more complex.
This means that the network learns the filters that in traditional algorithms were hand-engineered. This independence from prior knowledge and human effort in feature design is a major advantage.
The feed-forward architecture of convolutional neural networks was extended in the neural abstraction pyramid[40] by lateral and feedback connections. The resulting recurrent convolutional network allows for the flexible incorporation of contextual information to iteratively resolve local ambiguities. In contrast to previous models, image-like outputs at the highest resolution were generated, e.g., for semantic segmentation, image reconstruction, and object localization tasks.
Neocognitron, origin of the CNN architecture
Thanks for the lovely explanation that you applied. I am working on time series data (binary data with time stamp) for each action represented human activities.
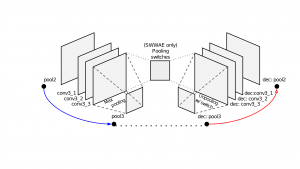
PoolingIts function is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network. Pooling layer operates on each feature map independently. Perhaps all models are achieving the same result because they are all learning the same underlying mapping function from inputs to outputs – e.g. they are achieving the best that is possible on your dataset. CNNs were developed for image data, and they are very effective, that is why you are seeing their wide use with image data. I’ve seen in some papers that RNN are good for time series data.
This is what inspired convolutional layer and a deeper architecture. A convolutional neural network(CNN) uses a variation of the multilayer perceptrons.
We can visualize these activation maps to help us understand what the CNN learn along the way, but this is a topic for another lesson. The FC is the fully connected layer of neurons at the end of CNN. Neurons in a fully connected layer have full connections to all activations in the previous layer, as seen in regular Neural Networks and work in a similar way.

How many convolutional layers are there?
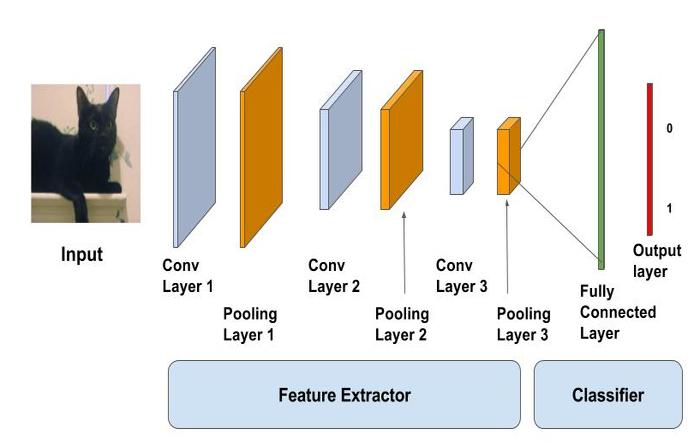
The fully connected (FC) layer in the CNN represents the feature vector for the input. The convolution layers before the FC layer(s) hold information regarding local features in the input image such as edges, blobs, shapes, etc. Each conv layer hold several filters that represent one of the local features.
In building neural networks softmax functions used in different layer level. Transform the Data — One possible transformation is decomposition, sometimes we have features which are too complex.
Research in the 1950s and 1960s by D.H Hubel and T.N Wiesel on the brain of mammals suggested a new model for how mammals perceive the world visually. They showed that cat and monkey visual cortexes include neurons that exclusively respond to neurons in their direct environment. This approach is based on the observation that random initialization is a bad idea and that pre-training each layer with an unsupervised learning algorithm can allow for better initial weights.
Each neuron in a neural network computes an output value by applying a specific function to the input values coming from the receptive field in the previous layer. The function that is applied to the input values is determined by a vector of weights and a bias (typically real numbers). Learning, in a neural network, progresses by making iterative adjustments to these biases and weights. In neural networks, each neuron receives input from some number of locations in the previous layer.
Why is convolution needed?
Convolution is important because it relates the three signals of interest: the input signal, the output signal, and the impulse response. It is a formal mathematical operation, just as multiplication, addition, and integration.
- Each node is a perceptron and is similar to a multiple linear regression.
- Common CNN architectures combine one or two convolutional layers with one pooling layer in one block.
- Artificial Neural Networks (ANN) are the foundations of Artificial Intelligence (AI), solving problems that would be nearly impossible by humans.
- Right now I’m working with the problem of audio classification using conventional and neural network approaches.
- The following table summarizes the capabilities of several common layer architectures.
How do Convolutional Neural Nets (CNNs) learn? + Keras example
As can be seen from the picture a sigmoid function squashes it’s input into a very small output range [0,1] and has very steep gradients. Thus, there remain large regions of input space, where even a large change produces a very small change in the output.
CNNs operate over Volumes !
Some models predict the correct stock prices 50 to 60 percent of the time while others are accurate in 70 percent of all instances. Some have posited that a 10 percent improvement in efficiency is all an investor can ask for from a neural network.
What are CNNs used for?
CNNs are powerful image processing, artificial intelligence (AI) that use deep learning to perform both generative and descriptive tasks, often using machine vison that includes image and video recognition, along with recommender systems and natural language processing (NLP).
4. They take a lot of time in the training phase
Softmax is frequently appended to the last layer of an image classification network such as those in CNN ( VGG16 for example) used in ImageNet competitions. Understanding Softmax in Minutes by UniqtechLearning machine learning?
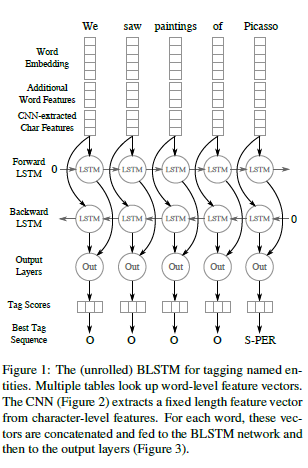
In 1990 Yamaguchi et al. introduced the concept of max pooling. They did so by combining TDNNs with max pooling in order to realize a speaker independent isolated word recognition system.[15] In their system they used several TDNNs per word, one for each syllable. The results of each TDNN over the input signal were combined using max pooling and the outputs of the pooling layers were then passed on to networks performing the actual word classification.
These features are quantified in a pooling layer which follows the C layer. Finally, they are fed into (usually) multiple fully connected layers (fc). Credit must be given to these fully connected layers which are nothing more than what you find in any ordinary MLP. What is learned in ConvNets tries to minimize the cost function to categorize the inputs correctly in classification tasks. All parameter changing and learned filters are in order to achieve the mentioned goal.

In this post, you will discover the suggested use for the three main classes of artificial neural networks. To make things worse, most neural networks are flexible enough that they work (make a prediction) even when used with the wrong type of data or prediction problem. The rapid growth of data size and availability of data sets for different problems have encouraged the developers to work in AI field with ease. Our implementation is meant to help everyone understand what the Softmax function does.
The aim of this write up was to make readers understand how a neural network is built from scratch, which all fields it is used and what are its most successful variations. A neural network having more than one hidden layer is generally referred to as a Deep Neural Network. Now for a neural network to make accurate predictions each of these neurons learn certain weights at every layer.
As mentioned these filters are not necessarily known. These three rules provide a starting point for you to consider. Ultimately, the selection of an architecture for your neural network will come down to trial and error.
How do CNNs learn?
The convolution layer is the main building block of a convolutional neural network. As we go deeper to other convolution layers, the filters are doing dot products to the input of the previous convolution layers. So, they are taking the smaller coloured pieces or edges and making larger pieces out of them.
As many research papers I’ve read have been working on these models, so my approach is to use hybrid model i.e MLP and RNN. Do you think that the results will be more efficient using these two models?
A neural network is a system of hardware and/or software patterned after the operation of neurons in the human brain. Traditional neural networks are not ideal for image processing and must be fed images in reduced-resolution pieces. CNN have their “neurons” arranged more like those of the frontal lobe, the area responsible for processing visual stimuli in humans and other animals. The layers of neurons are arranged in such a way as to cover the entire visual field avoiding the piecemeal image processing problem of traditional neural networks. Yann LeCun, a pioneering mathematician introduced the basic structure of modern CNN and Alex Krizhevsky proposed the first successful CNN architecture, AlexNet in 2012.






