$ 0.000 3.56%
LITEX (LXT) Rank 4895
| Mkt.Cap | $ 0.00000000 | Volume 24H | 0.00000000LXT |
| Market share | 0% | Total Supply | 2 BLXT |
| Proof type | N/A | Open | $ 0.0002 |
| Low | $ 0.0002 | High | $ 0.0003 |
OQEMA LITEX S 9070
The IP blocks within LiteX are completely open source, and so can be targeted across multiple FPGA architectures. However, for low-level synthesis, place & route, and bitstream generation, it still relies upon proprietary chip-specific vendor tools, such as Vivado when targeting Artix FPGAs. It’s a little bit like an open source C compiler that spits out assembly, so it still requires vendor-specific assemblers, linkers, and binutils. While it may seem backward to open the compiler before the assembler, remember that for software, an assembler’s scope of work is simple — primarily within well-defined 32-bit or so opcodes.
Previously, I had written about developing a reference design for the NeTV2 FPGA using Xilinx’s Vivado toolchain. Last year at 33C3 Tim ‘mithro’ Ansell introduced me to LiteX and at his prompting I decided to give it a chance.
Litex Surfaces – Gaudi Stone – 3200x1600mm Slab

As a result, the Vivado tool is pretty bad at optimizing designs for area. For example, the PCI express core – while extremely configurable and well-vetted – has no way to turn off the AXI slave bridge, even if you’re not using the interface. Even with the inputs unconnected or tied to ground, the logic optimizer won’t remove the unused gates. Unfortunately, this piece of dead logic consumes around 20% of my target FPGA’s capacity.
When powered on they will load their configuration from a flash chip (normally SPI flash) on the FPGA board. A SoftCPU is a CPU which is defined by a HDL (like Verilog, VHDL or Migen) and is included in the gateware inside a FPGA. As the definition can be changed when creating the gateware, SoftCPUs are highly customisable. LiteX code should be easily portable to Migen/MiSoC if legacy/experimental features are not used and is done regularly. firmware which runs on the Cypress FX2 USB interface chip attached to the FPGA.
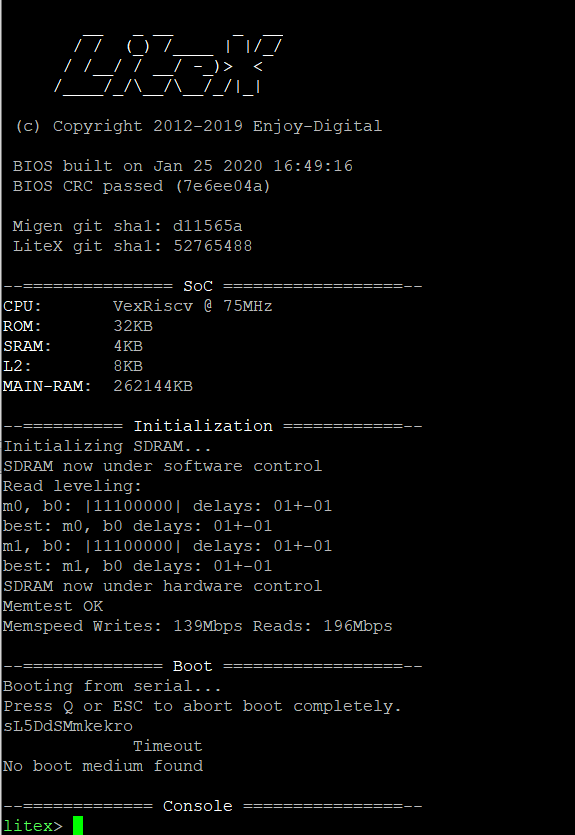
After a power cycle, the device will return to the flashed configuration. FPGAs (generally) loose their "configuration" when they loose power or are reset.
Flashing is sometimes done by loading a "flash proxy" gateware onto the FPGA, which then allows the computer to communicate with the flash chip. Flashing means to permanently put something (gateware, firmware, etc) onto a device. Tim mentioned that he thought the same design when using LiteX would fit in a much smaller FPGA.
Litex Surfaces – Varese Cenere – 3200x1600mm Slab

Thanks to the extensive work of the MiSoC and LiteX crowd, there’s already IP cores for DRAM, PCI express, ethernet, video, a softcore CPU (your choice of or1k or lm32) and more. To be fair, I haven’t been able to load these on real hardware and validate their spec-compliance or functionality, but they seem to compile down to the right primitives so they’ve got the right shape and size. The downsides of Vivado are that it’s not open source (free to download, but not free to modify), and that it’s not terribly efficient or speedy. Aside from the ideological objections to the closed-source nature of Vivado, there are some real, pragmatic impacts from the lack of source access. However, to attract design wins they must provide design tools and an IP ecosystem.

Litex T 52X60

Finally, the AXI fabric automation – while magical – scales poorly with the number of ports. In my most recent benchmark design done with Vivado, 50% of the chip is devoted to the routing fabric, 25% to the DDR3 block, and the remainder to my actual application logic. The fact that LiteX generates more efficient HDL means I can potentially shave a significant amount of cost out of a design by going to a smaller FPGA. Remember, both LiteX and Vivado use the same back-end for low-level sythesis and place and route. The difference is entirely in the high-level design automation – and this is a level that I can see being a good match for a Python-based framework.
But Xilinx has no incentive to add a GUI switch to disable the logic, because the extra gates encourage you to “upgrade” by one FPGA size if your design uses a PCI express core. Similarly, the DDR3 memory core devotes 70% of its substantial footprint to a “calibration” block. Calibration typically runs just once at boot, so the logic is idle during normal operation. With an FPGA, the smart thing to do would be to run the calibration, store the values, and then jam the pre-measured values into the application design, thus eliminating the overhead of the calibration block. However, I couldn’t implement this optimization since the DDR3 block is provided as an opaque netlist.
- The downsides of Vivado are that it’s not open source (free to download, but not free to modify), and that it’s not terribly efficient or speedy.
- Calibration typically runs just once at boot, so the logic is idle during normal operation.
- This means that despite my frustrations with the Python syntax, the penalty paid for small errors is much less in terms of time – so overall, I’m more productive.
- Vivado was empowering because instead of having to code up a complex SoC in Verilog, I could use their pseudo-GUI/TCL interface to create a block diagram that largely automated the task of building the AXI routing fabric.

However, Vivado tends to “fail late” – a small configuration problem may not pop up until about 20 minutes into the run, due to the clumsy way it manages out-of-context block synthesis and build dependencies. This means that despite my frustrations with the Python syntax, the penalty paid for small errors is much less in terms of time – so overall, I’m more productive. The main thing that’s got me excited about LiteX is the speed and efficiency of its high-level synthesis. LiteX produces a design that uses about 20% of an XC7A50 FPGA with a runtime of about 10 minutes, whereas Vivado produces a design that consumes 85% of the same FPGA with a runtime of about minutes. I was rewarded with a surprisingly powerful and mature framework for defining SoCs.
Litex Lovech Information
Migen is an HDL embedded in Python, and LiteX provides us with a Wishbone abstraction layer. There really is no reason we need to include a CPU with our design, but we can still reuse the USB Wishbone bridge in order to write HDL code. LiteX is a soft-fork of Migen/MiSoC – a python-based framework for managing hardware IP and auto-generating HDL.
He has been using LiteX to generate the FPGA “gateware” (bitstreams) to support his HDMI2USB video processing pipelines on various platforms, ranging from the Numato-Opsis to the Atlys, and he even started a port for the NeTV2. Intrigued, I decided to port one of my Vivado designs to LiteX so that I could do an apples-to-apples comparison of the two design flows. to read and write memory, and with a wishbone bridge we can actually have code running on our local system that can read and write memory on Fomu. Flashing is the process of writing a new configuration to the flash chip. Loading means to temporarily put something (gateware, firmware, etc) onto a device.

LiteX is hosted out of github, so the source code management is mature and “industry standard”. My final thought is that LiteX, in its current state, is probably best suited for people trained to write software who want to design hardware, rather than for people classically trained in circuit design who want a tool upgrade. There’s no question about the power and utility of the design flow – so, as the toolchain matures and documentation improves I’m optimistic that this could become a popular design flow for hardware projects of all magnitudes. Significantly, LiteX tends to “fail fast”, so syntax errors or small problems with configurations become obvious within a few seconds, if not a couple minutes.

You’re not really designing hardware with Python (eventually it all turns into Verilog) so much as managing and configuring libraries of IP, something that Python is quite well suited for. To wit, I dug around in the MiSoC libraries a bit and there seem to be some serious logic designs using this Python syntax. I’m not sure I want to wrap my head around this coding style, but the good news is I can still write my leaf cells in Verilog and call them from the high-level Python integration framework.
You can see that it takes very little code to take a Signal from HDL and expose it on the Wishbone bus. Flashing is generally slower than loading because it requires you to erase the contents of the flash, write the new contents and then verify the result. LiteX includes more experimental features that have not made it to Migen/MiSoC (and may never make it into Migen/MiSoC). LiteX includes legacy features removed from Migen+MiSoC which are still in use.

Additional information

For my tool flow comparison, I implemented a simple 2x HDMI-in to DDR3 to 1x HDMI-out design in both Vivado and in LiteX. Creating the designs is about the same effort on both flows – once you have the basic IP blocks, instantiating bus fabric and allocation of addressing is largely automated in each case.
I could only reclaim that space by hand-editing the machine-generated VHDL to comment out the slave bridge. It’s a simple enough thing to do, and it had no negative effects on the core’s functionality.
The development of this software is directly subsidized by the sale of chips. Vivado was empowering because instead of having to code up a complex SoC in Verilog, I could use their pseudo-GUI/TCL interface to create a block diagram that largely automated the task of building the AXI routing fabric. Furthermore, I could access Xilinx’s extensive IP library, which included a very flexible DDR memory controller and a well-vetted PCI-express controller. Because of this level of design automation and available IP, a task that would have taken perhaps months in Verilog alone could be completed in a few days with the help of Vivado.






